
לא קיים ארגון שלא רוצה לנצל את כוח הdata שלו כדי לפתור בעיות, לבסס החלטות ולשפר תהליכים תפעוליים ואסטרטגיים. לאור האתגר המורכב ארגונים משקיעים רבות בטכנולוגיות, בחברות ייעוץ ובאנשי Data (CDOs, Data Ops, Data Engineers, Data Architects). האם יש דמיון בין אתגרי Data לאתגרי העברת כבשים?!
יום אחד בנסיעה חזרה הביתה נחשפתי למחזה מדהים בדרך: עדר ענק של כבשים צועד כמו גדוד לצד הכביש ממש קרוב למכוניות הנוסעות וחשבתי לעצמי על האתגר הגדול של רועה הצאן לצד מעט הכלים שיש לו כדי לדאוג שהעדר יישאר כעדר ויגיע ליעד שלו ואחשוף כאן כמה "סודות" של רועה הצאן (עם קישור לאתגרי dataשארגונים גדולים חווים).
בתקופת התפרצות הגל השני של הקורונה זכיתי לחוות כמה אתגרי data בפיתוח פרויקט "Coview", פיתוח משותף של צה"ל עם משרד הבריאות לאיסוף מידע רפואי של מטופלי קורונה ממגוון מקורות (מוניטורים, מכונות הנשמה, מערכות תיק קליני) עבור תצוגות לרופאים ואחיות להחלטות על אופן הטיפול בכל מטופל קורונה.
אפשר בהחלט לומר על הקורונה שהיא מגפת הdata הראשונה בעולם. משרד הבריאות מוביל מאות פרויקטים לאיסוף, טיוב, אחסון וייצוא data הקשורים בקורונה. המידע הזמין שנצבר במערכות הללו מבסס החלטות ומחקרים רבים בעולם ובישראל להתמודדות בהווה ובעתיד עם המחלה (נתונים אפידימיולגיים, חיסונים, נתונים קליניים,..).
בסיום הנסיעה, כשהגעתי הביתה, החלטתי לחקור קצת ברשת את "אתגרי העברת הכבשים" ואתאר לכם מעט מהממצאים של האתגר היומיומי של רועה הצאן שבמסגרת תפקידו, צריך להוביל את הכבשים שלו פעם ביום למרעה וחזרה לדיר הכבשים. רועה הצאן חייב לתכנן טוב טוב את תהליך העברת הכבשים שלו מדיר הכבשים למרעה או ממרעה אחד לאחר. רועה צאן שלא מכיר את ה business, כנראה יגרום לכבשים שלו להתפזר, לצאת ממבנה העדר, לא להגיע ליעד או לבריחה המונית.
ראשית כל, רועה הצאן צריך לתכנן את המסלול שבו יעברו הכבשים שלו: כדי שהכבשים יעברו באופן מסודר מנקודה A לנקודה B, רועה הצאן צריך להכיר מראש את המכשולים במסלול שבו הוא רוצה להעביר אותן. המסלול המתוכנן צריך להתחשב מראש בסלעים גדולים, בדרך חסומה או בלתי עבירה או במעברי כבישים (מי מאיתנו לא ראה כבשים בצד הכביש ושאל את עצמו – זה היה בתכנון?) כדי שבזמן-אמת רועה הצאן לא יאלץ למצוא פתרונות יצירתיים כשמאות כבשים מתחילות לנוע לכיוון סכנה... מאוד קשה לשנות תהליכים לאחר שהData (סליחה הכבשים) כבר בתנועה.
מסלול ה data בארגון בדרך כלל מורכב מכמה משלבים :
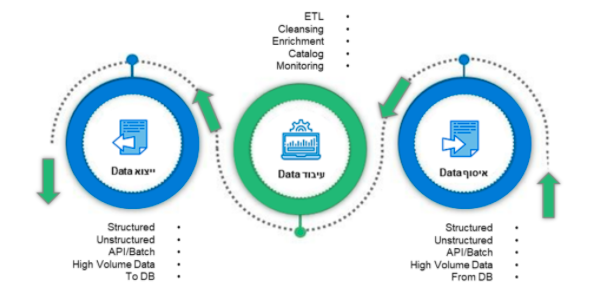
בשלב הראשון במסלול יש תהליך של איסוף data, שמטרתו התמודדות עם קליטה בתדירות גבוהה של נפחי מידע גבוהים וכאן כדאי לייצר תשתית גמישה וקלה לשכפול שיכולה להתבסס על כלי מדף או על קוד. התשתית צריכה בין היתר לאפשר התמודדות עם קליטת data ב batch, online או ב streaming, תאפשר קליטת מידע מובנה (structured), חצי מובנה ((semi-structured או לא מובנה (unstructured).
יש מספר כלי open source(מוכרים) שמבצעים תהליכי איסוף data בצורה טובה מאוד ומאפשרים לעבוד עם מגוון פורמטים, לשלב קוד ולבצע בקרה טובה על כשלים בתהליך.
בהמשך המסלול מגיעים לשלב עיבוד הdata שבו קיימים מספר תהליכים רלוונטיים (cleansing, enrichment,data-catalog ): בתהליכי ה data-cleansing וdata-enrichment המידע עובר טיוב, מנוקה ומועשר לפי הצרכים השונים, חלקו גם נזרק (לצערנו). התהליך הזה יכול לקחת דקות ארוכות ואף שעות, במיוחד אם המידע מועשר מכמה מקורות שונים או שהתהליך לא נבנה בצורה אופטימלית (למשל מעברים חוזרים ונשנים על רשומות שכבר נשלפו במסגרת תהליכים אחרים)
לטובת עיבוד הdata, ישנם גם כאן כלים חינמיים או בתשלום עם קילומטרז' רב. בחלק מהארגונים ישנה העדפה לתחזק בקוד תהליכי data-cleansing שנחשבים מורכבים משיקולי ביצועים או לאחסן "בחניית ביניים" את הנתונים בבסיס נתונים כך שניתן יהיה להריץ במקביל תהליכי cleansing ולהמשיך במקביל את תהליך איסוף ה data. בשלב הזה ניתן גם לעדכן את קטלוג המידע הארגוני - הdata catalog שמאפשר לארגון ללמוד סטטיסטיקות שונות על ה data ואת מבנה ה data החדש שנוצר בארגון.
השלב האחרון במסלול הוא ייצוא ה data לאחר שעבר טרנספורמציה ומכאן הוא יכול לעבור לתוך בסיס נתונים ארגוני שבנוי לקלוט אותו במבנה החדש שלו או להיות מיוצא לצרכנים שרוצים לצרוך אותו באחד מהאופנים שכבר הזכרנו בשלב הייבוא (api, batch או streaming).
צרכני הנתונים יכולים להיות פנים ארגוניים או חוץ ארגוניים ובכל אחד מהשניים מומלץ לייצר הפרדה מסודרת באופן העברת ה data בצורה של שירות (service) ולא לייצר קישור ישיר בתוך שכבת ה data (קישור כview, stored procedure או אחר). העלות המיידית של יצירת שירות כנראה גבוהה יותר אבל בטווח הארוך אי מימוש שירות יגרום לצמידות ותלות. יש גם כלי מדף שמאפשרים ללא מאמץ גדול ליחצן API החוצה לכל צרכן ולמנוע צמידות.
כמו בכל בחירה בחיים, גם להשקעה בכלי מדף חזקים לעומת השקעה באנשים חזקים שיכתבו קוד יש יתרונות וחסרונות, שאותם צריך לשקול ולקחת בחשבון: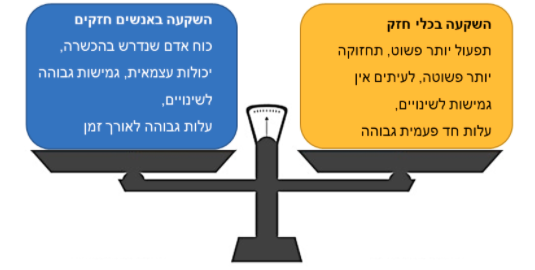
לא כל ארגון יכול להביא אנשי data תותחים שיבנו עבורו את ערוצי המידע ממגוון סיבות (חלקן קשורות לתקציב וחלקן קשורות לזמינות ולדחיפות הצורך). ארגונים שיכולים להשקיע הרבה באנשי data חזקים כנראה יכולים להשקיע קצת פחות בכלים. לחילופין, השקעה נמוכה יותר באנשים עלולה להסתיים בבעיית גמישות לשינויים שהכלים לא בהכרח מאפשרים.
נחזור לרגע לרועה הצאן שלנו ולמסלול שלו, הוא צריך להכיר מראש מכשול נפוץ במסלול שהכבשים יתקלו בו: מעבר צר שבו הכבשים צריכות לעבור למבנה צר כדי לעבור בו ולאחר מכן הן משנות שוב למבנה המקורי שלהן.
גם לאנשי data בארגון יש מכשול נפוץ של מעבר צר והם צריכים להכיר מראש את הנפחים והמגבלות שהנפחים עלולים לייצר כשהם עוברים בתחנות השונות בארגון. מומלץ שאנשי ה data יחזיקו "מחשבון" צמוד, כדי לחשב את גדלי ה data כפונקציה של כמות הרשומות והמידע בכל רשומה. החישוב יהווה בסיס להחלטות רבות כמו למשל, האם לטפל בdata באופן רציף או בתהליך מתוזמן בתדירות גבוהה/נמוכה.
בתהליך ה cleansing גם עלול להיווצר "מעבר צר" של data כיוון שהוא עלול להתארך מעבר לחלון הזמן שתוכנן עבורו (לעיתים משניות בודדות לדקות ארוכות ואף יותר).
לסיכום, הסוד הראשון של רועה הצאן וגם של אנשי ה data הוא תכנון המסלול מראש, כולל היערכות נכונה למעברים צרים בדרך. יש כמה סודות או טכניקות נוספות שרועי הצאן משתמשים בהן להעברת כבשים וקשורות במבנה של העדר ובניטור התנועה של העדר ועליהן נרחיב בהמשך.
זיו כהן בוגר ממר"ם, יזם וארכיטקט data במשרד הבריאות
