
לא קיים ארגון שלא רוצה לנצל את כוח הdata שלו כדי לפתור בעיות, לבסס החלטות ולשפר תהליכים תפעוליים ואסטרטגיים. לאור האתגר המורכב ארגונים משקיעים רבות בטכנולוגיות, בחברות ייעוץ ובאנשי Data (CDOs, Data Ops, Data Engineers, Data Architects). בחלק ב נספר על הסוד השני של רועה הצאן – שמירה על מבנה העדר.
כבשים ידועות בעיקר בזכות אינסטינקט העדר החזק שלהן ובעקבות המוטיבציה שלהן להישאר במבנה העדר. כבשה תשאף לברוח מגורם שמפחיד אותה ותשאף להתאגד בקבוצות גדולות לטובת ההגנה שלה. מבנה העדר הוא ההגנה היחידה שיש לכבשה מפני טורפים, קיימת לכבשה תחושת "בטיחות" במספרים הגדולים כיוון שלטורף יהיה קשה יותר לבחור כבשה מתוך קבוצה מאשר לנסות לטרוף כמה כבשים תועות. האינסטינקט חזק זה של הכבשה הוא המאפשר לבני אדם להניע כמויות גדולות של כבשים עם מעט משאבים.
הפעם נדבר על מבנה העדר שהוא הסוד השני של רועה הצאן שנדרש להוביל כמויות גדולות של כבשים לאורך מסלולים ארוכים. עיקרון חשוב מאוד של רועה הצאן בהובלת הכבשים הוא שמירה על מבנה העדר. כל עוד שרועה הצאן מצליח לדאוג לתנועה במבנה סדור של העדר, אז כך גם הכבשים התועות תשאפנה לחזור מהר למבנה הסדור וצעדיהן יהיו לכיוון שאליו הולך העדר.
ארגונים רבים עושים את צעדיהם לתוך עולם הdata בזמן שהם מחזיקים מערכות ותיקות שבהם הושקעו שנות אדם רבות ולצידן מעוניינים לשלבן עם טכנולוגיות חדשות, הם מעוניינים לשאוב ממערכות הlegacy נתונים שישולבו עם נתונים ממקורות נוספים (שיכולים להיות לא מובנים או חצי מובנים) שיכולים להגיע כעת בקצב גבוה ונפחים גבוהים.
המידע הארגוני הקיים במערכות ה legacy כנראה מאוחסן בבסיסי נתונים רלציונים (Relational Databases) ולטובת השילוב עם הנתונים החדשים הוקצו בסיסי נתונים רלציוניים ייעודיים (Staging Databases) שהם לעיתים העתק של בסיסי הנתונים של מערכות הlegacy ומבוצעים בהם תהליכי הטרנספורמציה על הdata בשילוב data שמגיע מבחוץ.
אילוץ זה עלול לגרום להשקעה רבה בזמן עיבוד ובמיפוי בתוך תהליכי הטיפול ב data: ייגזל זמן להתאמת מבנה הנתונים כדי לשמור את המידע בבסיס הנתונים הרלציוני (ייתכן עם קשרים לטבלאות נוספות), זמן ניקוי, טיוב והעשרת המידע יכול כנראה יקרה בטור ולא במקביל ולבסוף טרנספורמציה נוספת לקראת תהליך הייצוא של המידע.
בסיסי הנתונים של מערכות ה legacy בארגון שעד לא מזמן החזיקו את מרבית המידע בארגון, עלולים פתאום להחזיק רק נתח קטן מנפח המידע הכולל של הארגון ודווקא המשקל ינוע לכיוון המידע הלא מובנה שנקלט ממקורות אחרים.
ואז נשאלת השאלה האם כדאי לשקול מחדש את אופן אחסון המידע?
אבל לפני התשובה לשאלה הזו, אני רוצה להתייחס למספר הבדלים בין בסיסי נתונים רלציונים (Relational) לבסיסי נתונים לא רלציונים (Non-Relational):
בסיסי נתונים רלציוניים (Relational DBs) סך הכול מאוד פופולריים, הם החלו לצוץ חזק בשנות ה 90 (של המאה הקודמת) כתחליף הגיוני לשמירת ה data בקבצים שטוחים. הם מאפשרים לחלק את המידע בצורה לוגית בין טבלאות שונות ע"פ קשרים ולשמור מפתחות שיגדירו את הקשרים בין הטבלאות השונות.
שפת השאילתות ה SQL-ית מזכירה שפה טבעית ומהווה אבן דרך חשובה בתהליכי חפיפה של תוכניתנים, dba-ים ועוד. הJoinים שלה מאפשרים חיבור בין טבלאות והיא מאפשרת באופן יחסית פשוט ואינטואיטיבי לבצע שליפות מבסיס הנתונים.
לעומתם, בסיסי נתונים לא רלציוניים (NoSQL DBs / Non-Relational DBs) החלו להיכנס לשימוש לפני כ 14 שנה במטרה לתת מענה גמיש לנפחי מידע גדולים, מבנה הנתונים שמאפשר התמודדות עם המידע ללא קשרים בין ה"טבלאות" ומאפשר שמירת מידע היררכי (document), מידע שטוח ע"פ מפתחות (key-value), מידע עם כמות עמודות ענקית (column-based) או מידע המכיל קשרים רבים (graph-based).
בסיסי נתונים אלו נולדו מהדרישה לביצועים גבוהים, ליכולת Scaling מהירה (נראה בהמשך) לאחסון נפחי מידע גבוהים שהחלו להיות מיוצרים ממקורות מגוונים בשנים האחרונות: מידע מסנסורים, תמונות, לוגים של שרתים ואפליקציות, קבצי וידיאו ואודיו, אימיילים, מידע מרשתות חברתיות ועוד.
נמחיש את ההבדלים בין בסיסי הנתונים בצורה פשוטה מבלי לצלול לטכנולוגיה שתומכת בכך: ניקח לדוגמא מקרה שבו אנחנו מעוניינים לשאוב מידע מאתר אינטרנט שמחזיק Blogים של משתמשים ונראה איך ניתן לייצג את המידע בכל סוג בסיס נתונים.
נניח שכל Blog מורכב מפוסטים (posts) שמשתמשים יוצרים, מתגיות (tags) שונות שנוצרות באופן אוטומטי או על ידי המשתמש לכל פוסט ותגובות לכל פוסט (comments). מכיוון שבסיסי נתונים לא רלציוניים מחזיקים טבלאות עם כמות עמודות קבועה, אנחנו נאלצים לייצר הפרדה בין הפוסטים, התגיות והתגובות (כיוון שהם משתנים בגודל מפוסט לפוסט) – דבר שגורם לנו להחזיק 3 טבלאות שונות במבנה הרלציוני.
לעומת זאת, בבסיס נתונים לא רלציוני מסוג document ניתן להחזיק מידע היררכי אשר משתנה בגודלו. כל פוסט היה נשמר במסמך (document) אשר היה מכיל בצורה מקוננת את התגיות והתגובות. מבנה זה היה מייעל את החיפוש של הפוסט ושל המידע הנלווה: התגובות וההערות. כך זה יכול להיראות:
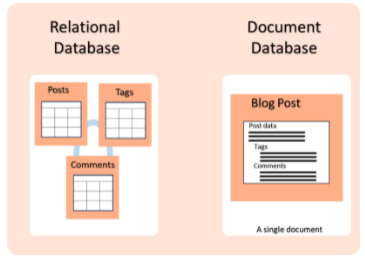
ואיך סוג בסיסי הנתונים מתחברים לתמונה הגדולה? כאשר אנחנו מייצרים ארכיטקטורה למסלול של הdata שכולל תהליכי איסוף –> עיבוד –> ייצוא. אנחנו יכולים לאסוף את ה data ישירות לבסיס נתונים לא רלציוני אשר מותאם כבר עם מבנה נתונים לdata שמגיע מבחוץ ושלב שינוי המבנה נחסך לנו, את המידע שנקלט בבסיס הנתונים ניתן להעשיר, לטייב ולנקות באופן יחסית יעיל ולחבר אליו שליפות נקודתיות מבסיסי הנתונים רלציוניים בארגון.
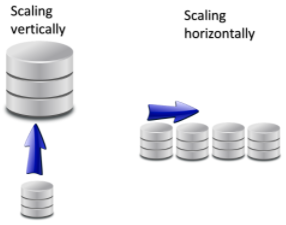
בדרך כלל, כאשר יש צורך בייעול עבודת בסיסי נתונים רלציוניים הפתרון הוא גידול/הרחבה אנכית Scaling vertically. במילים אחרות - הגדלת חוזק המכונות הקיימות.
בבסיסי נתונים לא רלציוניים קיימים מנגנונים של גידול/הרחבה אופקית Scaling horizontally, המאפשר הוספת שרתים (לא בהכרח חזקים יותר) שיחלקו ביניהם את המידע כך שניתן באופן יחסית פשוט לייעל את תהליך העבודה באופן מהיר ומבלי להשפיע על השרתים הקיימים.
מקור:pixabay.com
לא אכנס להמלצות ספציפיות על בסיסי נתונים, לאור העובדה שכל מקרה לגופו וכדי להיערך נכון, צריך לנתח את הארכיטקטורה הקיימת בארגון כדי להמליץ על הפתרון המיטבי.
רועה הכבשים שלנו כבר מבין שהוא צריך לדאוג לתכנון מסלול הכבשים וגם להכיר את חוק מבנה העדר כדי לשמור על הכבשים שלו יחד. אבל איך הוא יתמודד בכל זאת עם "כבשים תועות" ואיפה הוא וה"עוזרים" שלו צריכים להתמקם כדי להיות מוכנים לתקלות בלתי צפויות? על כך נדבר בפרק הבא...
זיו כהן בוגר ממר"ם, יזם וארכיטקט data במשרד הבריאות
